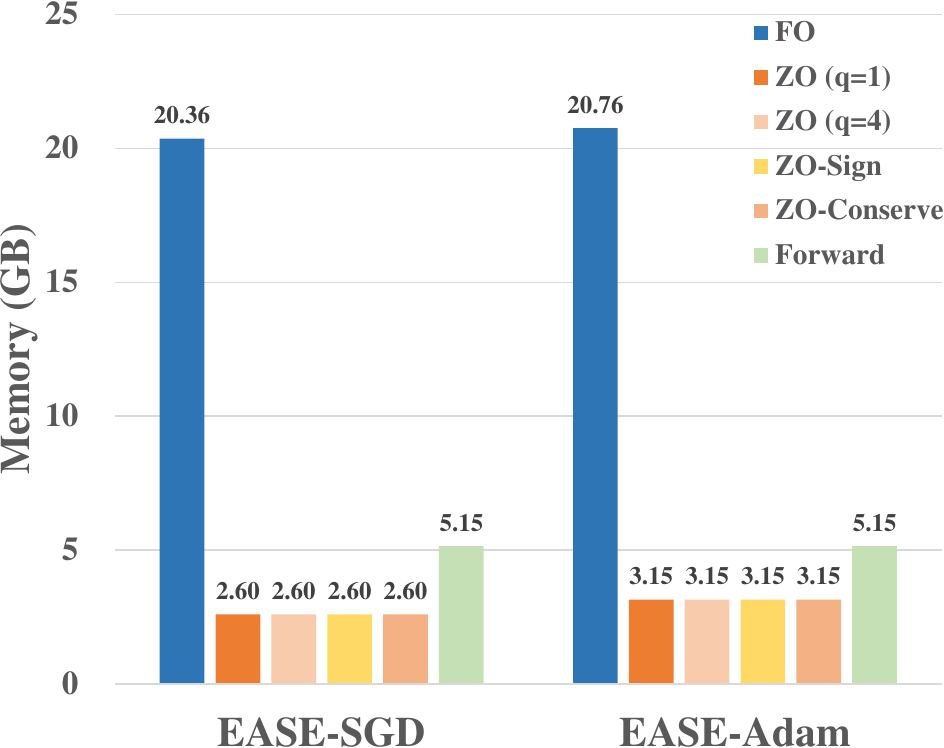
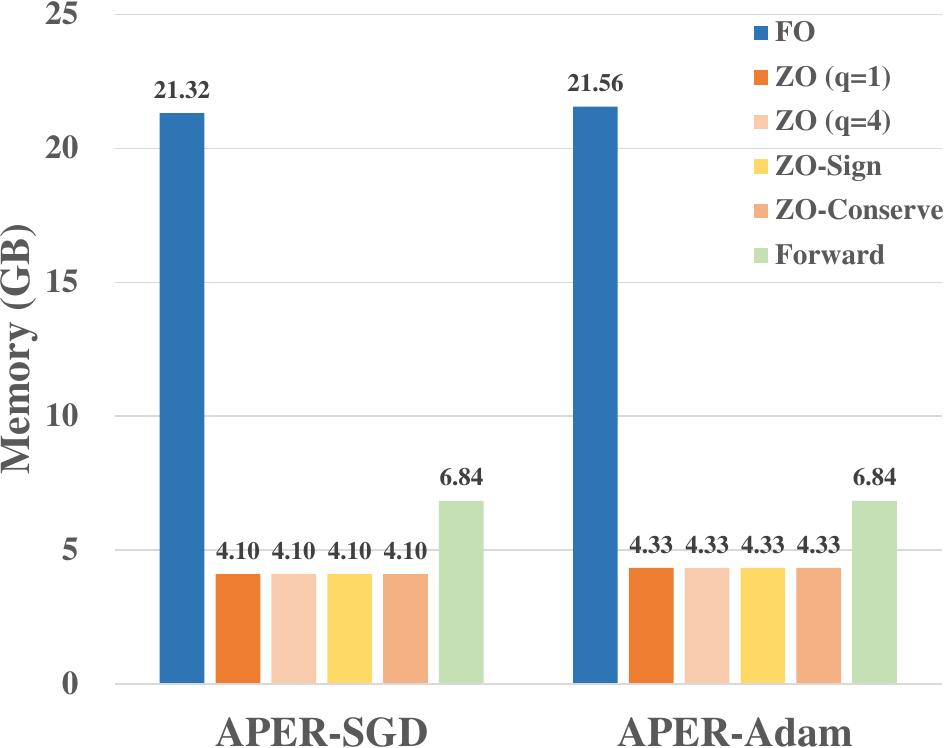
FO-SGD
Overview
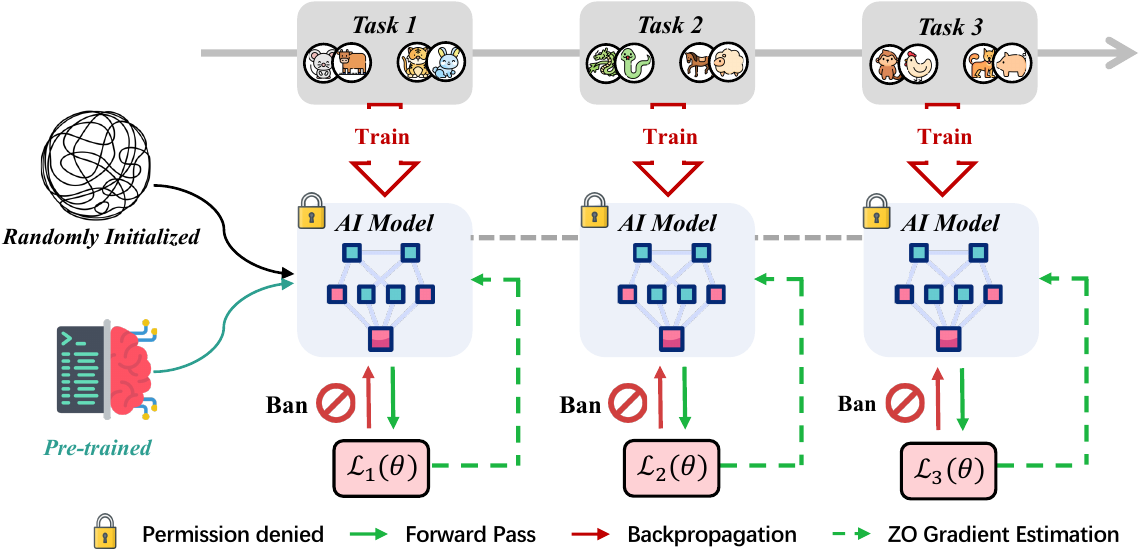
In real-world scenarios, gradient information is not always available or computable, often referred to as the "gradient ban," making traditional methods for overcoming forgetting unavailable, as backpropagation is restricted or not feasible. ZeroFlow method leverages zeroth-order (ZO) optimization to tackle catastrophic forgetting, focusing on dynamic data flow. By utilizing only forward passes, it eliminates the need for backpropagation, providing a cost-effective solution with minimal computational overhead. Its flexibility, through a range of ZO methods, ensures adaptability across different forgetting scenarios and model types.